
از گزارشهای Index Coverage برای پیدا کردن مشکلات ایندکس صفحات و حل آن استفاده کنید
اگر همه چیز در وبسایت شما درست باشید آنوقت گوگل کارهای زیر را انجام خواهد داد:
۱) پیدا کردن صفحه شما
و
۲) افزودن سریع آن به فهرست ایندکس صفحات
اما بعضی وقتها اوضاع اینطور پیش نمیرود. اتفاقاتی میافتد که شما باید آنها را رفع کنید تا گوگل آن صفحات را index کند.
و اینجا است که Index Coverage و گزارشهای آن به کمک ما میآیند.
اجازه بدهید بطور عمیق این مورد را بررسی کنیم.
گزارش Index Coverage در سرچ کنسول جدید چیست؟
گزارشهای Index Coverage به شما اجازه میدهد تا متوجه شوید کدام یک از صفحات شما index شده و کدام صفحهی شما بدلیل وجود مشکلات فنی index نشدهاند. شما در سرچ کنسول جدید میتوانید به صورت دقیق این موارد و ارور هایی که دارید را برسی کنید و آنها را برطرف کنید.
Index Coverage بخش جدید google search console است و جایگزین Index Status گوگل سرچ کنسول قدیم است.
توجه: بخش Index Coverage جدید بسیار پیچیده است.
و من فقط می توانم لیستی از ویژگی ها را برای شما تهیه کنم و برای شما آرزوی موفقیت کنم.
(در حقیقت این بخش خودش به یک راهنمای کامل و جامع جداگانه نیاز دارد)
درعوض، میخواهم شما را گام به گام با آنالیز واقعی یک وبسایت آشنا کنم
به این ترتیب می توانید من را مشاهده کنید که از گزارش Index Coverag برای پیدا کردن مشکلات استفاده می کنم … و آنها را رفع میکنم.
چطور خطاها را با استفاده از گزارش Index Coverag پیدا کنیم
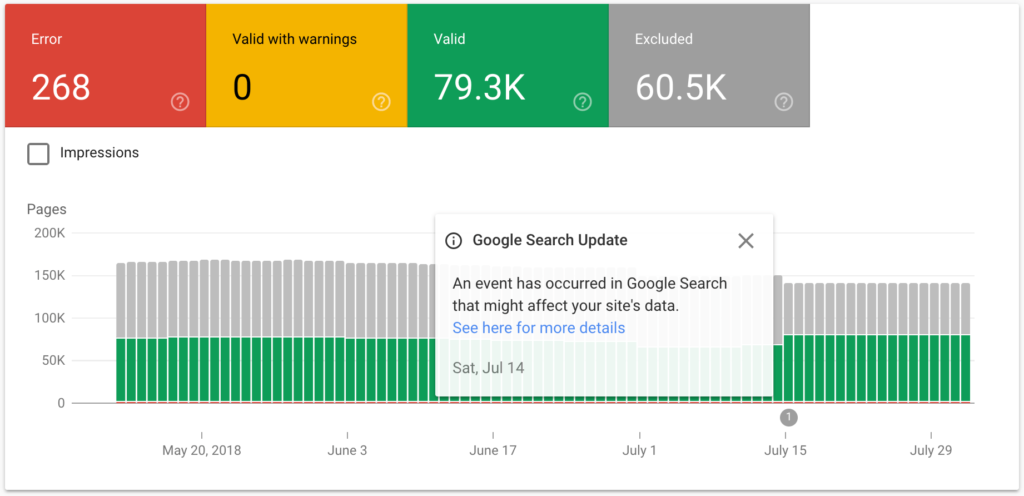
در بالای بخش Index Coverage report ما 4 تب را مشاهده میکنیم:
Error
Valid with warnings
Valid
Excluded
الان میخواهیم بر روی Error تمرکز کنیم.
همانطور که میبینید این سایت 54 خطا دارد.نمودار نشان می دهد که این شماره چگونه با گذشت زمان تغییر کرده است
اگر شما به سمت پایین صفحه اسکرول کنید میتوانید جزئیات هر یک از خطاها را ببینید.
کارهای زیادی هست که اینجا باید انجام دهیم.
بنابراین برای کمک به شما در درک هریک از این مشکلات ابتدا بطور مختصر هریک را تعریف میکنیم.
“Submitted URL seems to be a Soft 404”
به این معنی که این صفحه not found بوده ولی کدی غیرصحیح در header تنظیم شده است.
“Redirect error”
به این معنی که این صفحه ریدایرکت شده (302/301) اما به درستی کار نمیکند.
“Submitted URL not found (404)”
صفحه پیدا نشده و سرور کد http درست را برمیگرداند. (404)
“Submitted URL has crawl issue”
این مورد میتواند 100ها دلیل داشته باشد.
باید صفحه را ببینیم تا دلیل را پیدا کنیم.
“Server errors (5xx)”
رباتهای گوگل نمیتوانند به سرور دسترسی داشته باشند. این مشکل میتواند به علت خراب شدن سرور، Time Out، یا حتی از کارافتادن رباتهای گوگل باشد.
و وقتی شما بر روی یکی از این خطاها کلیک میکنید میتوانید صفحاتی که آن خطا را دارند را مشاهده کنید.
به نظر میرسد رفع خطای 404 آسان باشد پس، از آن شروع میکنیم.
بر روی یکی از صفحات کلیک میکنیم. حال منویی در سمت راست صفحه برای ما نمایش داده میشود که دارای 4 گزینه است.
اما اول اجازه دهید این آدرس را دوباره در مرورگر باز کنیم تا مطمئن شویم که این صفحه از دسترس خارج است.
بله ، صفحه از دسترس خارج است.
پس روی Fetch as Google در منو باز شده در گوگل سرچ کنسول کلیک میکنیم.
حال روی گزینه Fetch کلیک میکنیم
با این کار ربات گوگل سریعا صفحه شما را چک میکند.
مطمئنا، این صفحه هنوز کد 404 (Not found) را به من نمایش میدهد.
حال چطور این مورد را درست کنیم؟
خب ما 2 راه داریم:
1- آن را به حال خودش رها کنیم. در اینصورت گوگل بطور خودکار آن صفحه را deindex کرده و از جست و جو حذف میکند زیرا این درک را دارد که شما آن صفحه را از دست دادهاید. (مثل زمانی که دیگر نمیخواهید محصولی را به فروش برسانید)
2- آن را یه صفحهی دیگر مثل محصول، دسته بندی یا مقالهای در سایت ریدایرکت کنیم.
چطور خطای Soft 404 را برطرف کنیم؟
حال نوبت برطرف کردن این خطای مزاحم است. یعنی خطای Soft 404.
دوباره آدرس هایی که دارای این خطا هستند را بررسی می کنیم.
سپس، هر یک از آنها را در مرورگر مشاهده میکنیم.
به نظر میرسد که صفحه اول این لیست به درستی بازگذاری میشود و خطایی ندارد.
ببینیم که آیا گوگل نیز به این صفحه به درستی دسترسی دارد؟ پس دوباره روی Fetch as Google کلیک میکنیم.
ولی این بار روی Fetch and Render کلیک میکنیم. با این کار ربات گوگل به صفحه شما خواهد رفت و هرآنچه که میبیند را شما نیز میتوانید ببینید.
به نظر میرسد اینبار گوگل توانسته این صفحه را ببینید و پیدا کند.
حال ببینیم ربات گوگل این صفحه را چطور دیده است؟
به نظر میرسد به همان اندازه که یک بازدید کننده از سایت میبیند او نیز دیده است. این خیلی خوب است.
بعد به سمت پایین اسکرول میکنیم. در اینجا گوگل به شما مواردی را نشان میدهد که کاربر آن را در آن صفحه میبیند … ولی گوگل نمیتواند آن را کامل ببنید.
بعضی اوقات دلیل خوبی برای مسدود کردن منابع خاصی از Googlebot وجود دارد.
اما گاهی اوقات این منابع مسدود شده می توانند به خطاهای Soft 404 منجر شوند.
در این مورد، این 5 چیز بلاک شدهاند. پس ادامه میدهیم …
درآخر روی تب Fetching کلیک میکنیم تا از وضعیت کد http آگاه شویم.
خیلی خوبه! وضعیت 200 یعنی گوگل اینبار این صفحه را پیدا کرده و قابلیت index شدن را دارد.
چطور خطاهای دیگر را برطرف کنیم؟
شما میتوانید از همان فرآیند بالا که برای رفع خطای Soft 404 استفاده کردم برای رفع دیگر خطاها استفاده کنید.
1- صفحه را در مرورگر بازکنید
2- روی Fetch and Render کلیک کنید
3- در مورد آن خطایی که google search console به شما می گوید مطالعه کنید
4- وضعیت کد http آن صفحه را ببنید.
مثالهای کمی را برای شما آماده کردهام:
خطای انتقال (Redirect)
همه چیز اینجا خوب پیش میره
خطای خزنده (Crawl)
در اینجا هم مشکلی را نمیبینیم
خطای سرور (Server)
خطای سرور نیز به خودی خود ناپدید شده است.
حتما یک خطای موقت از سمت هاست بوده است.
با کمی کار شما به راحتی می توانید اکثر خطاهای مربوط به این بخش ها را یرطرف کنید.
چطور هشدارها (Warning) ها را در Index Coverage Report برطرف کنیم؟
شما را نمیدانم …
… اما من دوست ندارم هیچ شانسی در سئو را از دست بدهم.
این بدان معناست که وقتی یک نارنجی روشن “اخطار” را می بینم ، تعجب نمیکنم.
بنابراین به تب Valid with warnings در Index Coverage Report میرویم.
این بار فقط یک هشدار داریم و آن Indexed, though blocked by robots.txt میباشد.
همراه من باشید تا به شما بگویم.
گوگل سرچ کنسول به ما میگوید دسترسی به این صفحه توسط فایل robot.txt مسدود شده است. پس به جای کلیک بر روی Fetch As Google بر روی Test Robots.txt Blocking کلیک میکنیم.
با کلیک بر روی این گزینه ما به robot.txt tester ورژن قدیمی گوگل سرچ کنسول میرویم.
همانطور که میبینید، این آدرس توسط robot.txt مسدود شده است.
پس مشکل چیست؟
خب اگر شما بخواهید صفحهتان در گوگل index شود، شما باید این آدرس را unblock کنید.
اما اگر نمیخواهید این صفحه index شود، 2 راه پیش روی شماست:
1- تگ noindex,follow را به صفحهتان اضافه کنید و آن را در فایل robot.txt آزادسازی کنید.
2- با استفاده از URL Removal Tool برای همیشه از آن صفحه خلاص شوید.
اما چطور باید از ابزار URL Removal Tool استفاده کنیم؟ همراه من باشید ?
چطور از ابزار URL Removal Tool در سرچ کنسول باید استفاده کنیم؟
ابزار URL Removal Tool سریعترین و راحتترین راه برای حذف یک صفحه از index گوگل میباشد.
بر روی Google Index در سایدبار سرچ کنسول قدیم کلیک کنید و سپس بر روی Remove URLs کلیک کنید.
در آخر آدرس صفحه ای را که میخواهید از index گوگل حذف شود وارد کنید.
دوباره بررسی کنید که URL را درست وارد کرده اید ، سپس روی Submit Request کلیک کنید.
توجه: با استفاده از این ابزار آدرسهایی که وارد میکنید فقط 90 روز حذف میشوند و بعد از آن ربات گوگل دوباره به آن سر میزند.
اما اگر دسترسی آن صفحه را از طریق robot.txt مسدود کنید …
… بزودی آن صفحه از بین خواهد رفت
بررسی صفحات index شده برای خطاهای احتمالی
حال به سراغ تب Valid میرویم.
این تب به ما میگوید کدام یک از صفحات سایت ما index شده اند.
اما، در این صفحه باید به دنبال چه چیزی بگردیم؟ 2 مورد :
1- افت غیر منتظره (یا افزایش) صفحات index شده
به کاهش ناگهانی تعداد صفحات index شده توجه می کنید؟
این می تواند نشانه ای از اشتباه بودن چیزی باشد:
شاید تعداد زیادی از صفحات دسترسی Googlebot را مسدود کردهاند.
یا شاید شما به طور اشتباه تگ noindex اضافه کرده باشید.
به هرحال
شاید شما صفحات خود را تغییر داده باشید و شما باید این موضوع را بررسی کنید
حال به آن روی سکه برویم
اگر متوجه افزایش ناگهانی صفحات ایندکس شده باشید ، چه می کنید؟
دوباره، این ممکن است نشانه ای از اشتباه بودن چیزی باشد.
(به عنوان مثال ، شما ممکن است صفحات زیادی که مسدود شده بودند، آزاد کنید)
2- تعداد غیر منتظره ای از صفحات ایندکس شده
در حال حاضر 41 پست در Backlinko وجود دارد.
وقتی نگاهی به بخش valid در Index Coverage بیندازید قطعا انتظار دارید که با تعداد زیادی صفحات ایندکس شده روبرو شوید.
اما اگر بالای 41 صفحه بود؟ پس مشکلی است و من میروم که این مشکلات را برطرف کنم.
اوه! غیرقابل باور است … این چیزی است که من میبینم
نگران من نباشید چیزی نیست ؛)
مطمئن باشید که موارد حذف شده واقعا حذف شده باشند
حالا:
دلایل زیاد و خوبی وجود دارد تا موتو جستجو از ایندکس کردن برخی از صفحات خود داری کنند.
شاید یک صفحه ورود باشد.
شاید صفحهای باشد که محتوای تکراری دارد.
یا شاید هم صفحهای باشد که کیفیت مناسبی ندارد.
توجه: منظورم از کیفت پایین این نیست که آن صفحه بدردنخور است. شاید آن صفحه برای کاربر مناسب باشد ولی برای موتور جست و جو خیر.
این میگه:
شما میخواهید مطمئن شوید صفحاتی که میخواهید ایندکس شود را گوگل حذف نمیکند.
در این مورد ما صفحات حذف شده بسیاری داریم.
و وقتی به پایین صفحه scroll کنیم لیستی از صفحاتی را میبینیم که به دلایل مشخصی توسط گوگل ایندکس نشده است.
حال بطور خیلی ریز هریک از این دلایل را بررسی میکنیم:
“Page with redirect”
صفحه به صفحهی دیگری منتقل شده است.
در مجموع اتفاق خوبی است. مگر این بک لینک یا لینکهای داخلی وجود داشته باشد که به این صفحه برسند. در اینصورت آنها دیگر ارزشی ندارند و ایندکس نمیشوند.
“Alternate page with proper canonical tag”
گوگل یک جایگزین مناسب برای این صفحه در جای دیگر پیدا کرده است.
این همان کاری است که تگ Canonical انجام میدهد. پس این هم اوکی هست.
“Crawl Anomaly”
این مورد میتواند دلایل زیادی داشته باشد و باید بررسی کنیم.
مثلا در مورد ما صفحات خطای 404 را برمیگردانند.
“Crawled – currently not indexed”
هوووووم! …
این صفحه توسط خزندههای گوگل بررسی شده ولی به دلایلی ایندکس نشده.
و گوگل هم به شما علت دقیق آن را نمیگوید.
اما بر اساس تجربهی من: این صفحات ویژگی و دلایلی ندارند که گوگل آنها را ایندکس کند.
پس برای حل این مشکل باید چه کاری انجام دهیم؟
پیشنهاد میکنم: کیفیت آن صفحات را افزایش دهید.
مثلا اگر آن صفحه، صفحهی دسته بندی شما است به آن دسته بندی توضیحات اضافه کنید. اگر آن صفحه خیلی زیاد محتوای تکراری دارد آن محتوا را برای آن صفحه منحصر به فرد کنید. اگر محتوای کمی در صفحه دارید آن محتوا را افزایش دهید.
در یک جمله، آن صفحه را شایستهی ایندکس شدن در گوگل کنید
“Submitted URL not selected as Canonical”
در واقع گوگل میگوید:
این صفحه دارای محتوای تکراری از سایر صفحات است و ما فکر میکنیم دیگر صفحات بهتر هستند.
در نتیجه ما آن را از ایندکس گوگل حذف کردهایم.
پیشنهاد میکنم:
اگر محتوای تکراری از یک صفحه در خیلی از صفحات دیگر دارید به آن صفحات تگ noindex را اضافه کنید تا آن صفحهای که برایتان مهم است و محتوای آن خاص است ایندکس شود.
“Blocked by robots.txt”
اینها صفحاتی هستند که در robot.txt دسترسی خزندههای گوگل به آنها بسته شده است.
دوباره این خطاها را بررسی کنید تا مطمئن شوید این صفحات را به درستی مسدود کردهاید.
اگر robot.txt را بررسی کردید و همه چیز درست بود پس جای نگرانی نیست.
“Duplicate page without canonical tag”
این صفحه دارای بخشی از صفحات تکراری است و تگ canonical هم ندارد.
در مورد ما، خیلی راحت میتوانیم مشاهده کنیم که چه خبر است :
ما تعداد زیادی کتاب الکترونیکی که داریم محتوای آنها از دیگر صفحات سایت است.
این هشدار بزرگی نیست ولی اگر میخواهید این مورد هم برطرف شود به توسعه دهنده سایت خود بگویید این فایلها را در فایل robot.txt قرار دهد و دسترسی رباتهای گوگل را به آنها مسدود کند. در اینصورت گوگل فقط محتوای اصلی را ایندکس میکند.
“Discovered – currently not indexed”
گوگل آن صفحات را Crawl کرده ولی هنوز آنها را ایندکس نکرده است.
“Excluded by ‘noindex’ tag”
همه چیز خوب است و تگ noindex کار خود را به خوبی انجام میدهد
این بود بخش گزارشهای Index Coverage. مطمئنم که الان به حیاتی بودن این ابزار پی بردید.
بررسی گزارش HTML Improvements (بهبود HTML)
من کدنویس نیستم.
اما این را میدانم که پیچاندن زیاد کدهای html میتواند به سئو سایت شما لطمه بزند.
و این مورد بطور خاص برای تگ عنوان و توضیحات صدق میکند.
بطور خلاصه، هر صفحه سایت شما باید شامل موارد زیر باشد:
1- عنوان منحصر به فرد (تقریبا بین 65 تا 70 کاراکتر)
2- متا توضیحات منحصر به فرد (تقریبا تا 300 کاراکتر)
هریک از صفحات سایت شما
(بله، حتی اگر شما یک فروشگاه اینترنتی با میلیونها صفحه داشته باشید)
خوشبختانه، پیدا کردن مشکلات HTML سایت در گوگل سرچ کنسول بسیار راحت است.
وقتی صفحه HTML Improvements را باز میکنیم گوگل به ما خواهد گفت که چه خبر است:
به اطلاعات بیشتری نیاز دارید؟ با کلیک روی هر دسته بندی میتوانید اطلاعات بیشتری را نسبت به هر مشکل بدست آورید.
آیا این مقاله برای شما مفید بود؟
- اپراتور شماره 1 چاپ و تبلیغات سرویس های طلایی
- 18 مهر 1398
- 1769 بازدید
- بروزرسانی : 23 اسفند 1402
اشتراک گذاری :